The search for five nines (highly available IT services)
High levels of uptime are essential for critical applications as they ensure the availability and reliability of services and applications. Downtime can result in financial losses, reputational damage, regulatory fines, and decreased customer satisfaction. Uptime, or availability, is often measured in “nines,” with five nines being considered the gold standard.
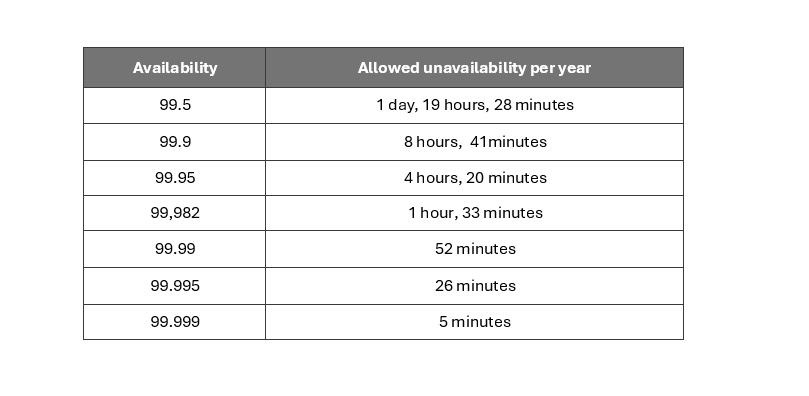
However, it’s easy to misinterpret claims on availability. Components will differ in expected uptime; for example, traditional storage arrays have higher availability SLAs than virtual machines, which makes sense as data loss can be far more disruptive than losing a front-end web server. We could try calculating service availability by determining the availability of individual components and then combining the SLAs. For example, (0.99982 * 0.99999 * 0.995 = 0.99481095). This would give us a combined SLA of 99.4811%, notice the overall system availability being slightly lower than the worst individual SLA due to the combined effect of potential downtimes.
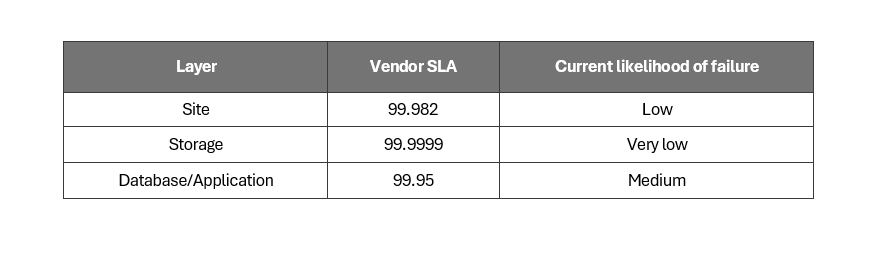
The number of components used by a service and its dependencies make this calculation difficult, as single points of failure are not allways obvious until something breaks.
Design and architecture, or the combination of components, are vital. Having a data center with 99.999% uptime makes no sense if a service depends on non-redundant components with poor availability. For example, look at the tables below for single instance Azure Virtual Machines, the SLA for the VM should be consistant, but notice its the SLA of disk type that affects of the overall SLA.
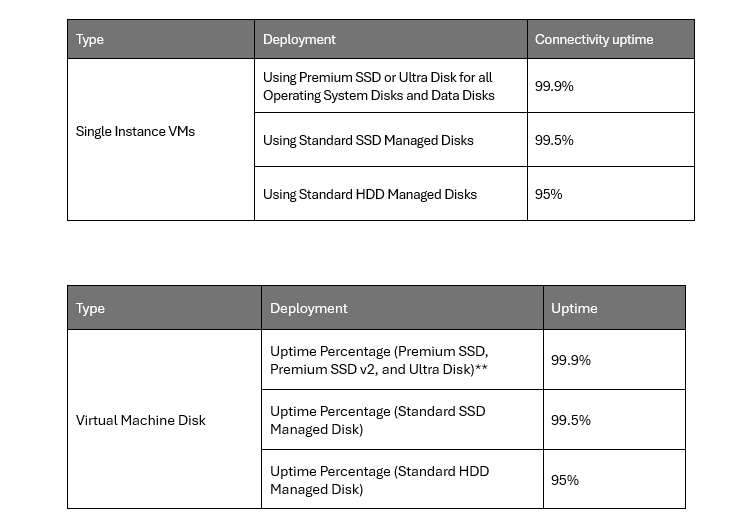
The SLA for multiple instances is much better, however the application needs to be distributed, which can be done at the application level or with a load balancer. This is the pattern in public cloud, building high availability at the application and database layers and using multiple instances on independant infrastucture in two or more physical locations.

Spreading services across sites or infrastucture (fault domains) to improve availability reduces dependency on the underlying infrastructure and may be the vendor’s preferred method for availability. Even so, we need to understand the capability of the critical business service, for example: native SAP database synchronization only protects against data loss. There is a primary active system and a secondary standby system; during a failure, downtime will be required while the secondary database takes over. Over-architecting the infrastructure will not elminate that downtime.
For legacy applications, high availability at the application layer may not be possible or was not considered when the service was deployed, it is important to understand moving workloads from a VMware vSphere Metro Storage Cluster (vMSC) to two Availability Zones in publc cloud does not result in the same recovery senario.
In conclusion.
- Don’t develop a false sense of security from SLAs with many 9s. Take a holistic view of the architecture, especially the database or stateful services.
- Some single points of failure, such as DNS, BGP, or the control plane, have caused major downtime for some of the world’s best-engineered services.
- Humans are guaranteed to make mistakes at some point. I’m not sure what is our MTBF (Mean time between failure), but an SLA of 99.999 is unlikely.